
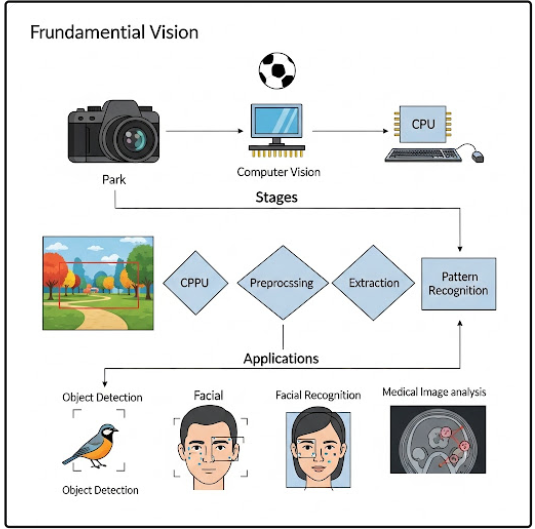
La visión por computadora (o visión artificial) es un campo de la inteligencia artificial que busca capacitar a los ordenadores para «ver» y comprender el mundo visual de manera similar a como lo hacemos los humanos. Esto implica permitir que las máquinas identifiquen, procesen y analicen imágenes y videos para obtener información y tomar decisiones.
En la parte de la IA que se enfoca en la visión por computadora, se incluyen varios componentes y sub-áreas clave:
1. Componentes de Hardware:
- Iluminación: Esencial para realzar el contraste y minimizar las variaciones de la luz ambiental, simplificando el procesamiento posterior. Puede ser frontal, trasera, con diferentes tipos de luz (LED, halógena, fibra óptica, etc.).
- Lentes y Ópticas: Encargados de enfocar la luz en el sensor, garantizando la mejor imagen con la menor distorsión posible.
- Cámaras Industriales/Sensores de Imagen: Son el «ojo» del sistema. Convierten la energía lumínica en señales eléctricas. Pueden ser:
- Monocromáticas: Detectan la intensidad de la luz (blanco y negro), ideales para aplicaciones donde el color no es relevante y se necesita alta resolución.
- Color: Capturan imágenes con color cuando es un factor importante.
- Tipos de sensores: CCD (Charge-Coupled Device) y CMOS (Complementary Metal-Oxide Semiconductor), siendo CMOS más común por su velocidad y costo.
- Cámaras especializadas: Cámaras RGB-D (profundidad), cámaras de tiempo de vuelo (ToF), cámaras infrarrojas/térmicas, cámaras multiespectrales, etc., según la aplicación.
- Procesadores de Visión / Plataformas Informáticas: Dispositivos con la capacidad computacional para analizar las imágenes adquiridas por la cámara (ej. PC industriales, FPGA, sistemas embebidos, o incluso la propia cámara en el caso de las «smart cameras»).
- Cableado y Periféricos de Interfaz: Para la conexión y comunicación entre los diferentes componentes del sistema.
- Otros dispositivos (en entornos industriales): PLC (Controladores Lógicos Programables) para interactuar con otras máquinas y activar/desactivar señales, pantallas para monitoreo, etc.
2. Componentes de Software y Procesamiento:
- Adquisición de Imágenes: El software interactúa con el hardware para capturar las imágenes.
- Preprocesamiento de Imágenes: Limpiar y mejorar la imagen (ej., reducción de ruido, corrección de contraste, normalización).
- Segmentación de Imágenes: Dividir una imagen en regiones o «objetos» significativos. Los métodos incluyen:
- Segmentación semántica: Asignar una etiqueta de clase a cada píxel (ej., «coche», «peatón»).
- Segmentación de instancias: Distinguir instancias individuales de objetos dentro de la misma clase (ej., «coche 1», «coche 2»).
- Segmentación panóptica: Combina semántica e instancias para una comprensión completa de la escena.
- Otros: Segmentación basada en regiones, basada en bordes.
- Descripción y Extracción de Características: Identificar elementos importantes de la imagen (formas, texturas, colores, patrones).
- Reconocimiento de Patrones y Clasificación: Comparar los patrones detectados con una biblioteca de patrones conocidos para identificar objetos específicos. Esto a menudo implica el uso de:
- Aprendizaje Automático (Machine Learning): Se entrenan algoritmos con grandes cantidades de datos visuales etiquetados para que el sistema aprenda a reconocer patrones.
- Aprendizaje Profundo (Deep Learning): Un subcampo del aprendizaje automático que utiliza redes neuronales artificiales con múltiples capas para aprender representaciones complejas de los datos visuales, lo que ha revolucionado la visión por computadora.
- Toma de Decisiones: Basándose en el análisis de las imágenes, el sistema puede tomar decisiones o activar acciones (ej., «pieza defectuosa», «persona detectada», «vehículo debe frenar»).
- Comunicación: Interfaz con otros dispositivos o sistemas para enviar los resultados o controlar procesos.
3. Tareas y Aplicaciones Comunes de la Visión por Computadora:
- Detección de objetos: Identificar la presencia y ubicación de objetos específicos en una imagen o video.
- Reconocimiento facial: Identificación de individuos a través de sus rasgos faciales.
- Seguimiento de objetos: Monitorear el movimiento de objetos a lo largo del tiempo en videos.
- Análisis de vídeo: Extraer información significativa de secuencias de vídeo (ej., detectar eventos, analizar el comportamiento).
- Control de calidad e inspección: Detectar defectos, verificar el montaje de piezas, asegurar la conformidad del producto en líneas de producción.
- Metrología: Realizar mediciones precisas de objetos.
- Lectura de códigos: Reconocimiento óptico de caracteres (OCR) para extraer texto de imágenes, lectura de códigos de barras, QR, etc.
- Robótica y Automatización: Guiar robots para manipular objetos (ej., «bin picking»), navegar en entornos.
- Vehículos autónomos: Percibir el entorno, detectar obstáculos, reconocer señales de tráfico, asistencia al conductor.
- Seguridad y Vigilancia: Detección de intrusos, monitoreo de personas, análisis de anomalías.
- Medicina: Diagnóstico de enfermedades (análisis de imágenes médicas), asistencia a personas con discapacidad visual.
- Agricultura de precisión: Detección de plagas y enfermedades, clasificación de frutos, monitoreo de cultivos.
- Comercio minorista: Tiendas autónomas (Amazon Go), probadores virtuales.
- Entretenimiento: Realidad aumentada (RA).
En resumen, la visión por computadora es un campo multidisciplinar que combina hardware especializado con algoritmos avanzados de IA para permitir que las máquinas interpreten y actúen en base a la información visual.